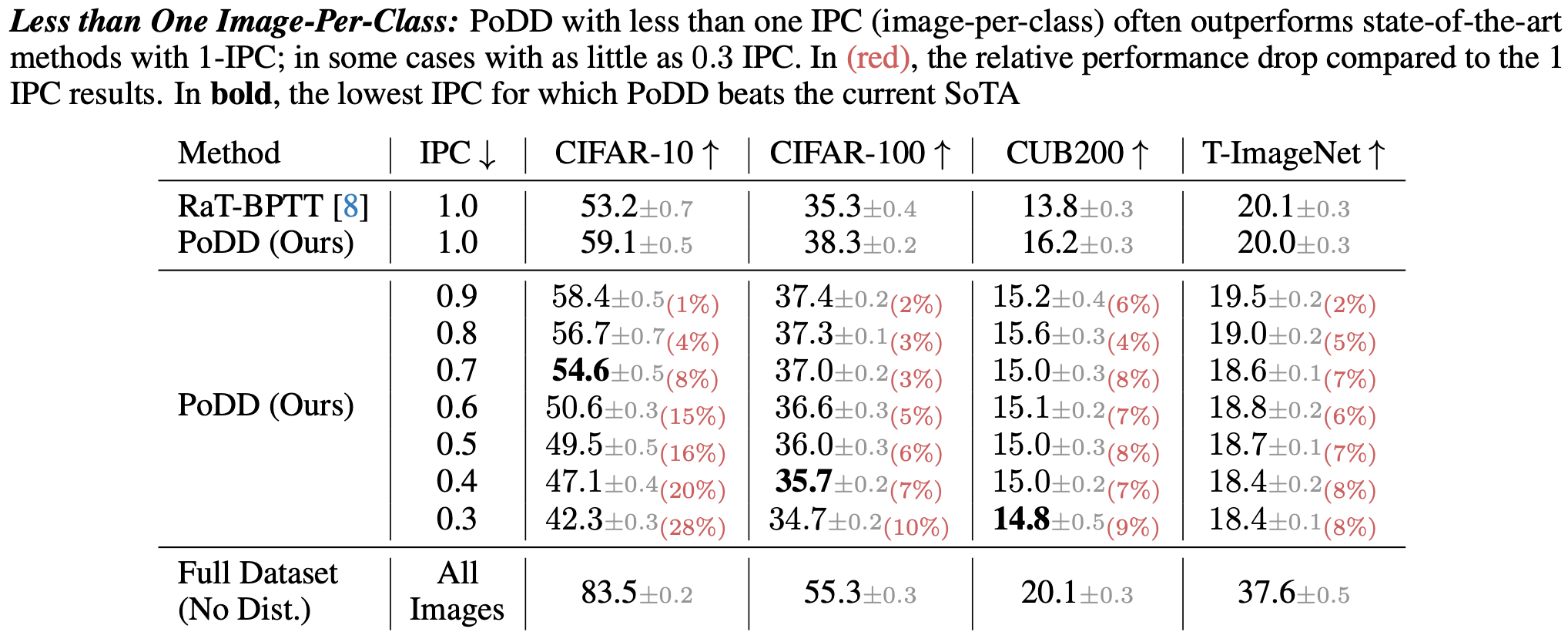

Dataset Compression Scale
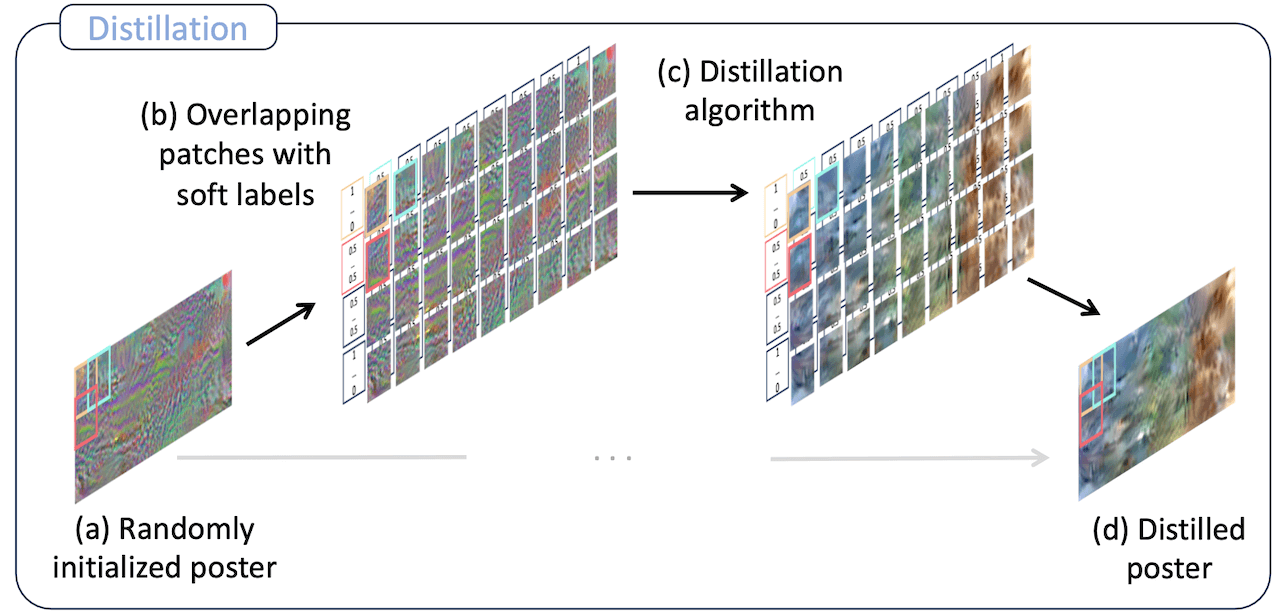
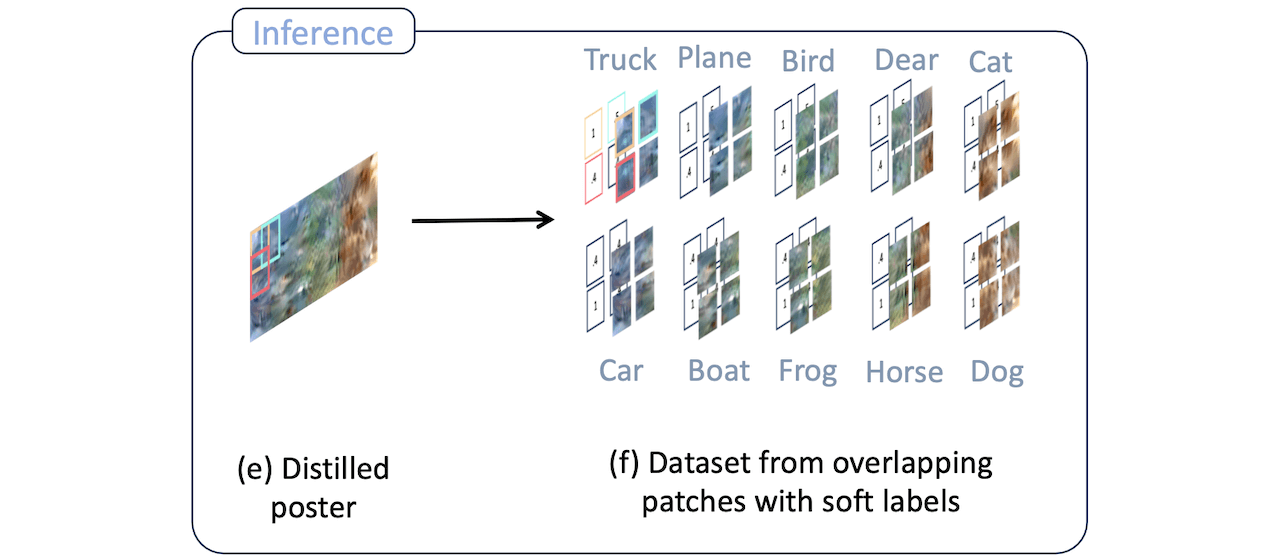
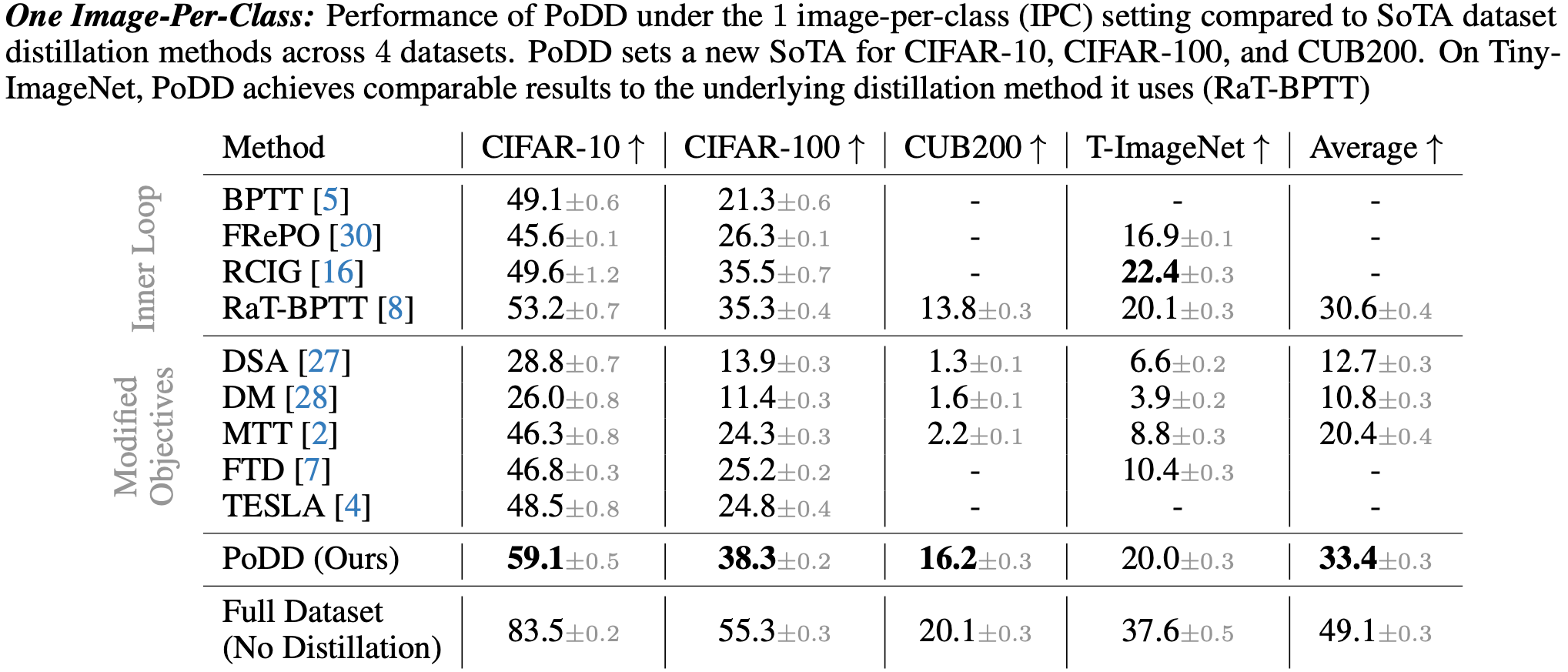
In this paper, we ask: "Can we distill a dataset into less than one image-per-class?" Existing dataset distillation methods are unable to do this as they synthesize one or more distinct images for each class. To this end, we propose Poster Dataset Distillation (PoDD), which distills an entire dataset into a single larger image, that we call a poster. The benefit of the poster representation is the ability to use patches that overlap between the classes. We find that a correctly distilled poster is sufficient for training a model with high accuracy.
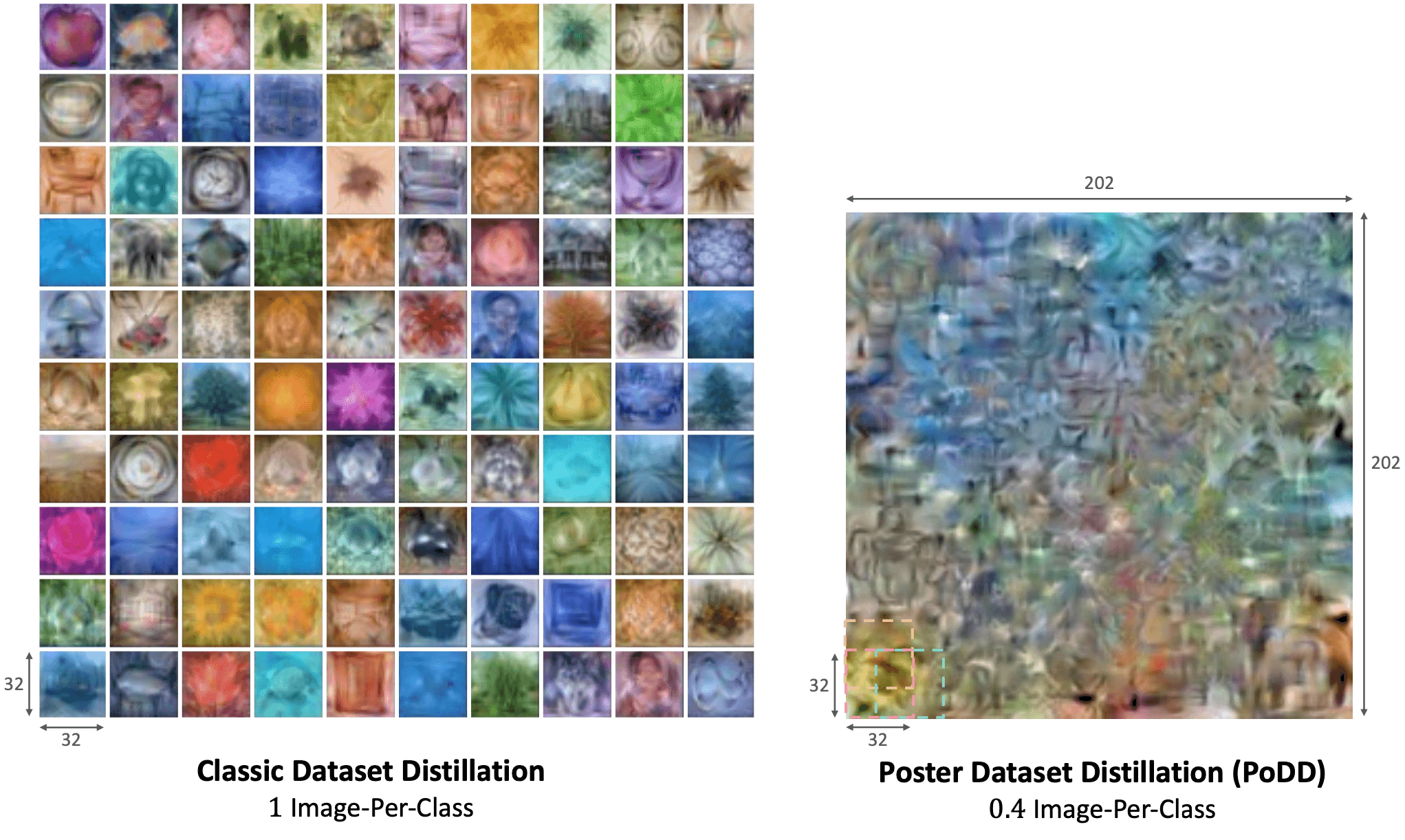
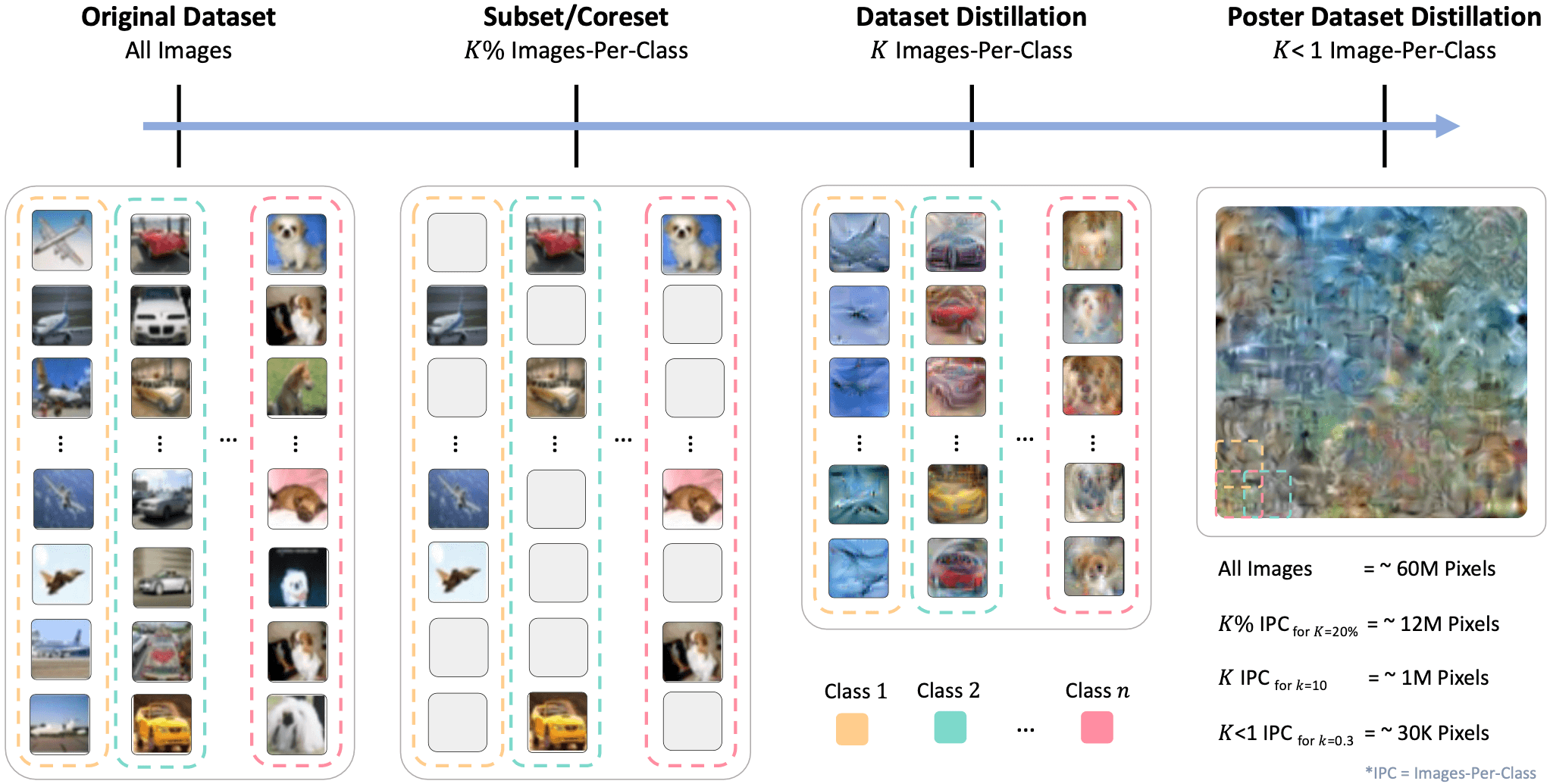 Dataset Compression Scale: We show increasingly more compressed methods from left to right. The original dataset contains all of the training data and does not perform any compression. Coreset methods select a subset of the original dataset, without modifying the images. Dataset distillation methods compress an entire dataset by synthesizing K images-per-class (IPC), where K is a positive integer. Our method (PoDD), distills an entire dataset into a single poster that achieves the same performance as 1 IPC while using as little as 0.3 IPC
Dataset Compression Scale: We show increasingly more compressed methods from left to right. The original dataset contains all of the training data and does not perform any compression. Coreset methods select a subset of the original dataset, without modifying the images. Dataset distillation methods compress an entire dataset by synthesizing K images-per-class (IPC), where K is a positive integer. Our method (PoDD), distills an entire dataset into a single poster that achieves the same performance as 1 IPC while using as little as 0.3 IPC